
A high-performant software for handling real-time data in low latency is known as Kafka. Kafka provides a high-throughput and distributed event-store system. Initially developed by LinkedIn to track activities, collect application metrics and logs, etc. Later Kafka is managed by Apache. So, it becomes Apache Kafka.
Real-time data feeds are continuous streams of data coming from N number of sources like sensors, CCTV on-road traffic monitoring, software applications (serving different purposes), etc. Speed, Volume, and variety of data coming to ingest in real-time is a stream of events.
Requirement:
- Storing data (event streams) for lateral uses – Durability.
- Processing or manipulating in real-time.
- Respond to event streams in real-time and also later (Batch Processing).
- Routing event streams to different destinations at the right time.
To handle the above critical requirements, we require high-performant software called Apache Kafka.
How Kafka works fasts?
Kafka manages streams of events at the rate of 100K messages per second is the reason Kafka is called a high throughput system. It is just one of the core capabilities of Apache Kafka.
Reason for Kafka to be a High-Throughput system:
- Sequential I/O.
- Zero Copy Principle.
Sequential I/O
As we all know, Kafka stores data (events) in Topics and Topics distributed in multiple brokers in partitions. All the records/events are stored in file storage. File storage is organised into blocks and every block has its unique address. So, fetching the same from random locations instead of sequential takes an exceptionally longer period of time if storing data on random locations.
Instead, sequentially write records one after the other and have their offset number (index number) to recognise while reading by N number of consumers. That is why, Kafka follows Sequentional I/O instead of Random I/O to perform faster.
In the case of Random I/O, jumping around to different locations (non-contiguous) to read and write records brings a slower process. But Sequential I/O works from contiguous blocks of memory which allows the read and write process faster.
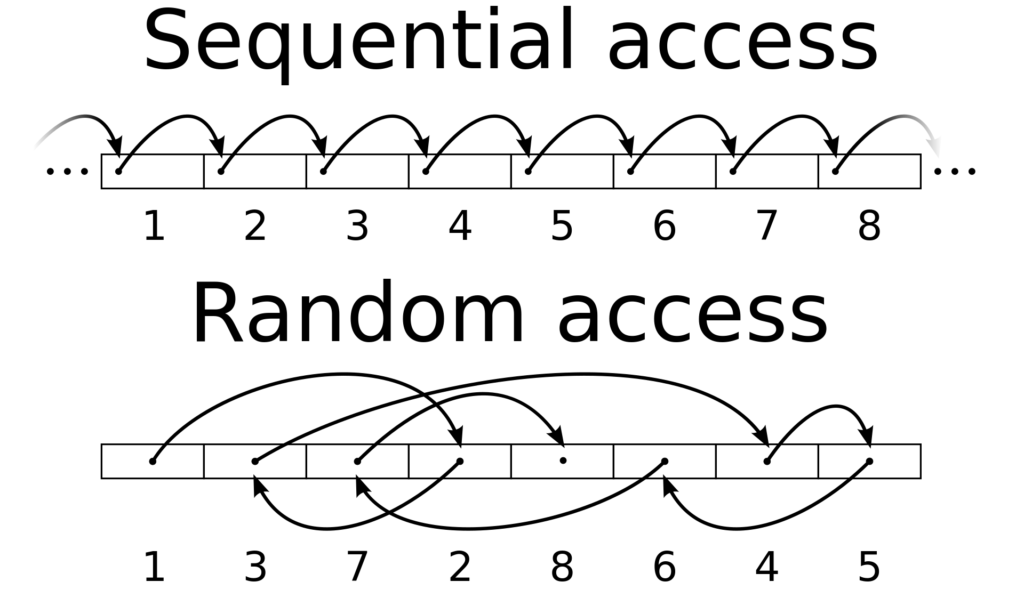
Kafka follows a log-based storage system which means new records are appended to the last of the log files. Following sequential I/O is one of the key factors to achieve high throughput.
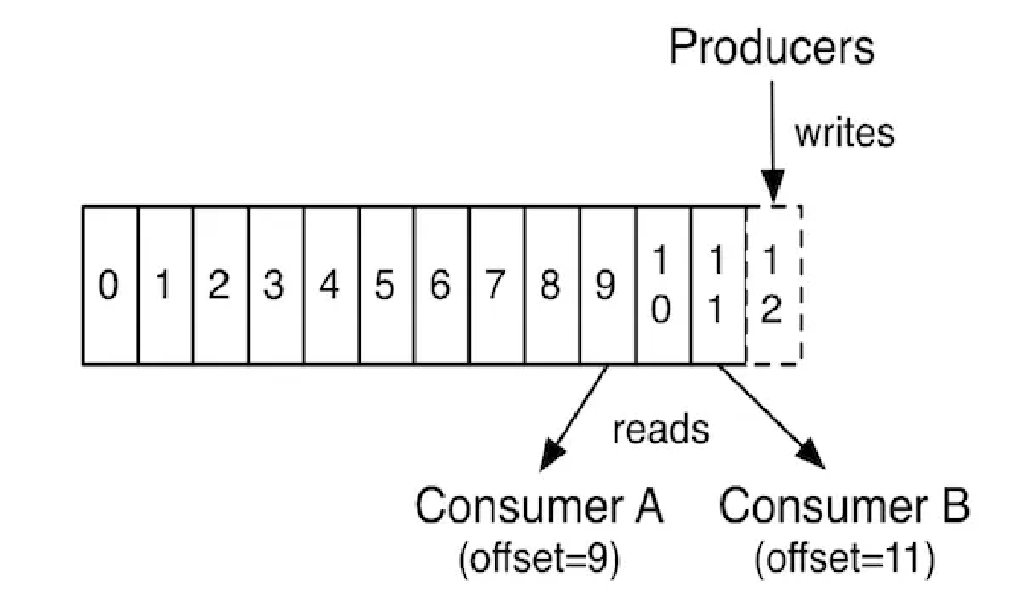
Zero Copy Principle
The zero-copy principle means bypassing the intermediate locations. In the traditional approach, when data needs to copy from the source location to the destination location, there are temporary buffer areas where data is copied first from the source and then goes to the final destination. This process is used CPU resources and memory usage as well.
The zero-copy principle eliminates the intermediates buffers and directly transfers data from source to destination. So, this technique significantly improves the performance of the system.
So, when multiple consumers read data from Kafka Topics, they are using DMA (Direct Memory Access) without involving any intermediate buffer and extensive CPU / memory usage.
These two techniques Sequential I/O and Zero Copy Principle help Kafka to achieve High-Throughput software.
References: